
Exploring Thermodynamic AI
A Playground for interacting with thermodynamic computing, which may be a key component for scaling AI that can reason, and navigate uncertainties.

Authors:
Max Hunter Gordon, Adrian Tan, Maxwell Aifer, Kaelan Donatella, Denis Melanson,
Gavin Crooks, Patrick J. Coles

A New Computing Paradigm
The AI revolution has captured people’s imagination, but it also has brought to the forefront various issues with the current AI stack. Hallucinations and overconfidence in large language models are very active fields of research and have highlighted the need for reliable, adaptive, and auditable AI. However, principled probabilistic reasoning - which is the basis for making AI reliable - is computationally expensive. This emphasizes the need for probabilistic hardware accelerators.
Indeed, the need for novel computing hardware has been emphasized by Geoffrey Hinton, who noted the mismatch between modern AI algorithms and current digital hardware. Hinton proposed a future where hardware and software are inseparable, and where the hardware is variable, stochastic, and “mortal”.
Thermodynamic AI represents a step towards this vision. It is a new computing architecture where the fundamental building blocks are inherently stochastic. An example of this is shown in the circuit diagram below, involving a resistor, capacitor, and voltage noise source, such that the voltage at point 1 evolves stochastically over time.

Our R&D team at Normal Computing detailed this physics-based computing paradigm in February in this arxiv paper, and we recently extended the application space of Thermodynamic Hardware to linear algebra primitives. (See this talk for an overview.) Now, we are giving everyone the opportunity to explore these theoretical ideas in a live Playground.
The Thermo Playground
Here we present our “Thermo Playground”, which is the subject of this blog post. The goal of the Thermo Playground is to give the user a feel of what it would be like to interact with the first iteration of Thermodynamic computing hardware. Try out this playground, and enjoy!
We invite the reader to join us on a journey into the future of computing, where the hardware is inherently uncertain, probabilistic, and physics-based. The Thermo Playground gives a glimpse into this exciting future. It will give you a feel for the various hardware dials and free parameters in Thermodynamic AI Hardware, and hopefully it will also show you how to start thinking thermodynamically, with the end goal of writing software and algorithms for this hardware.
In addition to illustrating the Thermo Playground, this blog post will highlight a key use-case of Thermodynamic Hardware, namely, for enabling large-scale methods for reliable AI.
Unlocking reliable AI
Imagine receiving a medical diagnosis from an autonomous AI agent, as depicted below. Complex systems like the human body require nuanced and careful treatment, and AI overconfidence can be catastrophic in situations where human lives are at stake.

The path to reliable AI goes through principled probabilistic reasoning, often called Bayesian reasoning or uncertainty quantification. Uncertainty estimates can inform the AI agent when to defer to human expertise, e.g., in the case of medical diagnosis.
However, it comes at a price! Adding reliability to AI generally adds computational overhead associated with uncertainty estimation. Often this involves Monte-Carlo methods, which involve sampling from a high-dimensional probability distribution. The challenge of high-accuracy sampling has notoriously been highlighted for Bayesian neural networks, where researchers have essentially argued that high accuracy is both crucial for performance as well as computationally intractable with current digital hardware.
Our vision for Thermodynamic AI hardware aims to solve this key problem, enabling fast sampling of complex, high-dimensional probability distributions, in order to unlock scalable, reliable AI.
We envision that the introduction of this innovative hardware paradigm will facilitate the development of novel machine learning applications. Through a feedback codesign loop, the collaboration between hardware and software will lead to their synchronized evolution, ultimately giving rise to advanced algorithms that would have been infeasible to execute on alternative hardware platforms. This concerted effort will enable us to explore uncharted territories in the realm of machine learning and push the boundaries of what can be achieved in this field.
The Stochastic Processing Unit (SPU)
With this motivation in mind, let us shift our attention to viable approaches to Thermodynamic Hardware. Our initial perspective on Thermodynamic Hardware, which we call the Stochastic Processing Unit (SPU), can be viewed as an electrical version of a coupled oscillator system. (See figure below for a mechanical analog.)
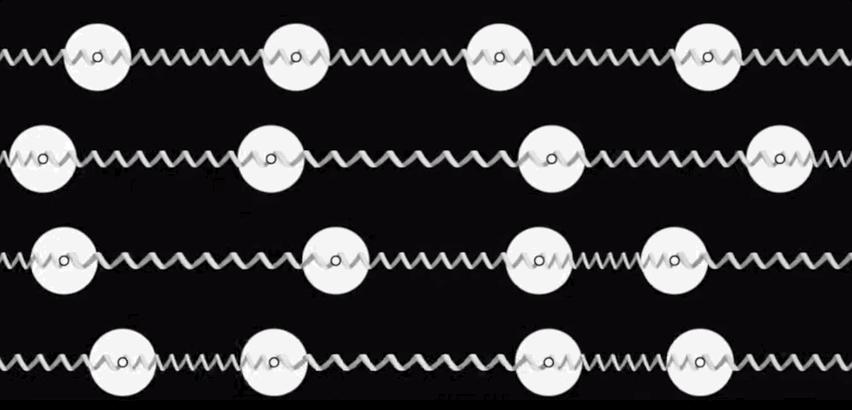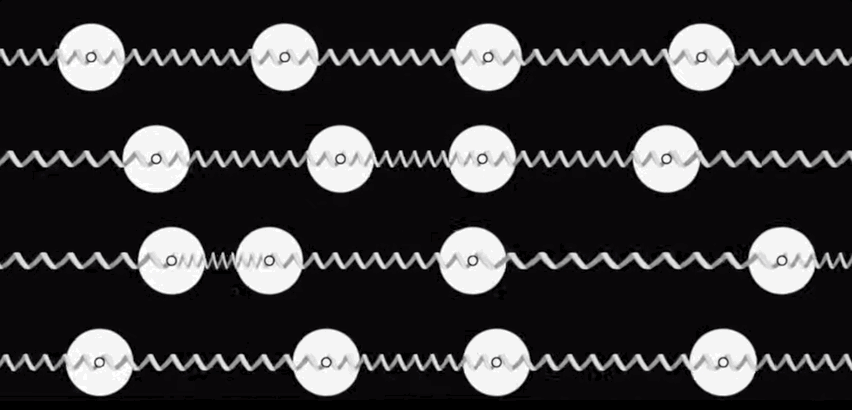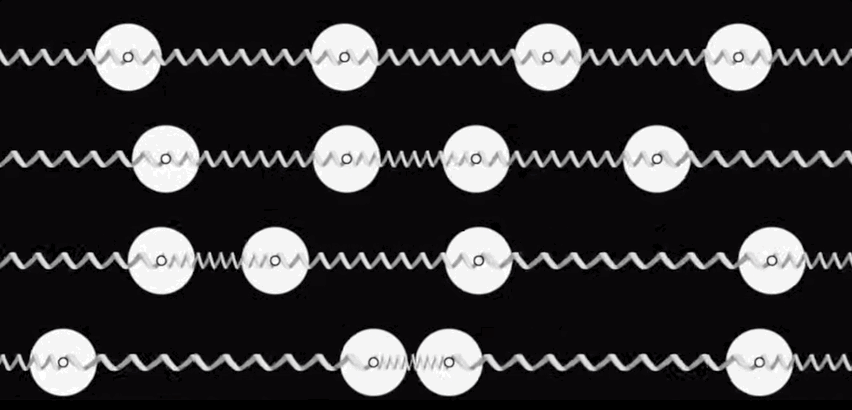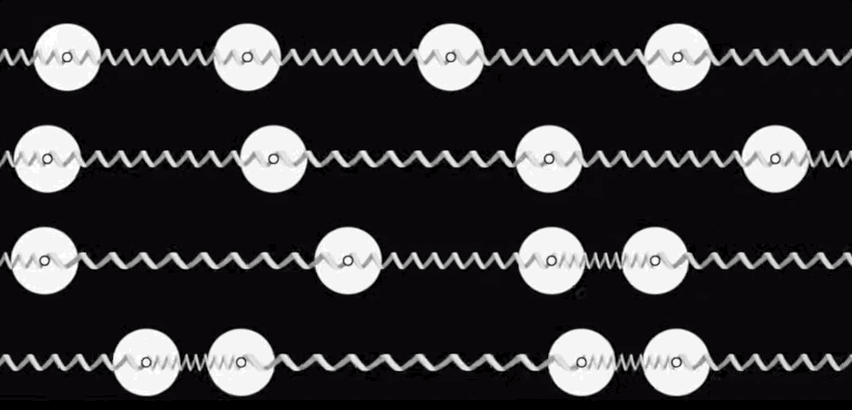
Each unit cell (as shown at the beginning of this blog) is an electrical oscillator, and they can be coupled together through resistive or capacitive coupling. The overall dynamics can be understood as a Langevin process and can be modeled with coupled stochastic differential equations, with free parameters that correspond to the particulars of the underlying electrical components.
Digital discretizations of Langevin dynamics are commonly used in Markov Chain Monte Carlo (MCMC) sampling algorithms. We are essentially removing the discretization and running the algorithm in continuous time on the SPU hardware. By allowing the SPU hardware’s parameters to be freely programmed, the user gets to choose the probability distribution that they wish to sample from.
The key difference with digital hardware is that, within the SPU, the samples are generated through the natural dynamics of the system, meaning they potentially could be generated faster, cheaper, and more energy efficiently.
With this in mind, let’s take a look at the playground!
Sampling with the Thermo Playground
Having introduced the SPU, let us now explore the results that it produces in the playground!
Suppose that you wish to sample from a Gaussian distribution, which is a crucial task for reliable AI (not to mention other fields like finance and forecasting). In the case of a 2D Gaussian, our playground allows you to choose the covariance matrix of the distribution, as well as the SPU hardware parameters like sampling time, temperature, resistance, and inductance.
The overall interface looks like this:
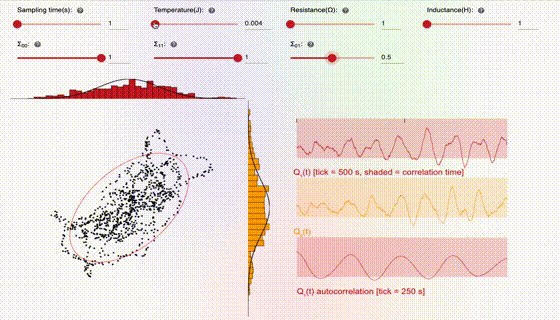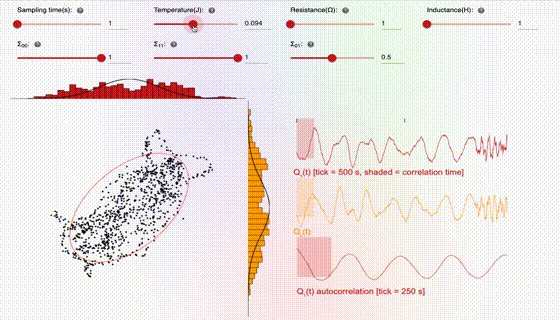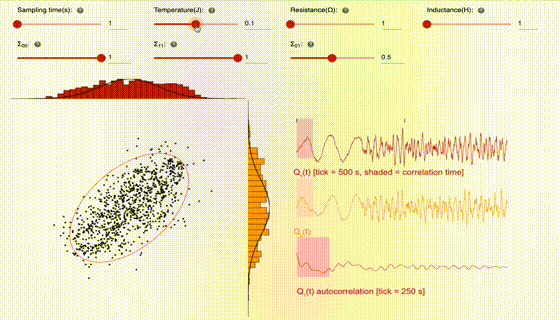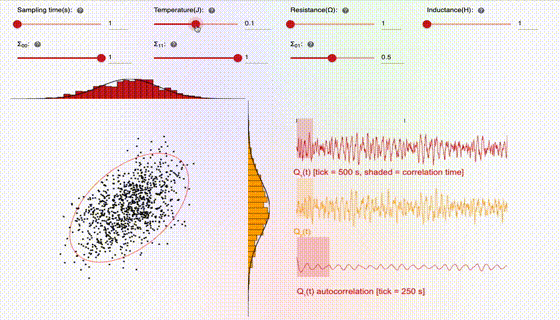
This interface consists of three key pieces, which are broken down below: (1) the knobs, (2) the 2D sampling plot, and (3) the 1D time-series traces. Let’s first start with the knobs:
The user can adjust the sampling time, which is the time the hardware waits between gathering a new sample. Choosing the sampling time to be too short can lead to correlated samples, which is generally undesirable, since the samples should ideally be independent. The user can also adjust the temperature, which is directly related to the amplitude of the stochastic noise. As one can see in the animation, higher temperature leads to more stochastic jumping, which often leads to better sampling since it tends to lead to samples which are less correlated. The resistance and inductance knobs allow the user to adjust the parameters of the SPU circuit. Resistance tends to damp out stochastic fluctuations, so increasing resistance can lead to more deterministic trajectories, and hence more correlated samples. Inductance is analogous to mass or inertia, and tends to slow down the overall dynamics.
The 2D sampling plot gives a visual representation of the target distribution (the solid red circle represents the covariance matrix) and the generated samples (shown as black dots). In addition, the projections of the 2D samples onto the 1D axes are shown as histograms on the top and side of the plot. For comparison, the marginals (i.e., the 1D distributions) associated with the target distribution are shown as solid curves, overlaid with the histograms.
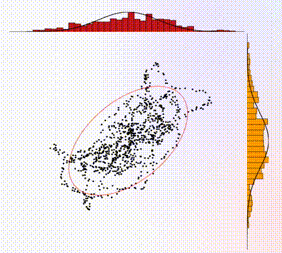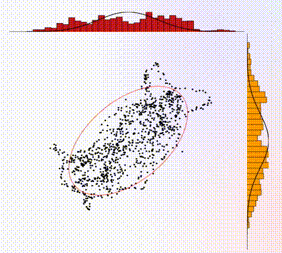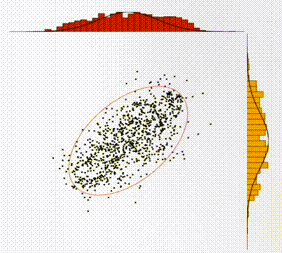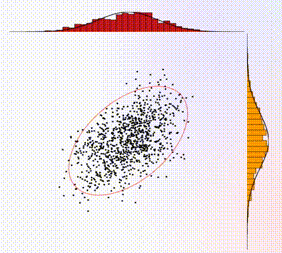
The 1D time-series traces show the two components of the samples in real time. A maximum of 1000 samples are allowed in the time window. Hence once this threshold is reached, old samples are discarded as new ones come in. In addition, there is a shaded box overlaying with the time-series trace, which illustrates the theoretical correlation time, i.e., the time over which samples are correlated. For ideal behavior (independent samples), one would want this shaded box to be small.
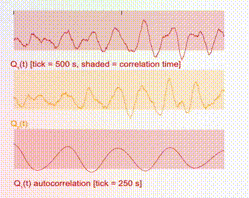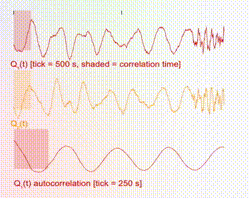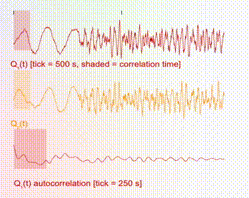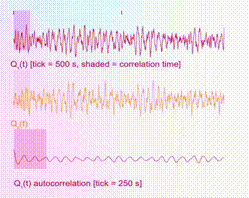
So that is the heart of the Thermo Playground! Now let us put this in the broader context of reliable AI.
Overconfidence of traditional AI approaches
Employing Large Language Models (LLMs) to high-stakes use cases such as medical/legal advice or enterprise workflows has yet to be fully unlocked due to their overconfidence and lack of reliability.
To get some appreciation of what overconfidence looks like in AI, let us consider a simple toy example of classifying the well-known 'two moons' dataset, a dataset of two intertwined half-circular shapes, resembling two crescent moons. The task is to train a classifier to distinguish between the 'left moon' and the 'right moon.' In the figure below, these are represented as blue and orange dots.
ResNet, a popular convolutional neural network, can solve this task with high accuracy. When presented with in-distribution data points (those that lie on the crescents), it classifies them accurately, as seen in the figure below (left plot).

However, challenges arise when we consider out-of-distribution (OOD) data points, those that do not lie on either of the two moons but in the empty space around them. The ResNet model will still make a confident prediction on OOD data, attributing them to one of the two moons with high certainty. This is shown in the figure above, where the test points in red are predicted with zero uncertainty to belong to the same class as the orange moon.
Let us now see how to resolve this issue of overconfidence on OOD data.
State-of-the-art Uncertainty Quantification
For classification with neural networks, a promising solution for dealing with the overconfidence is Spectral Normalized Gaussian Processes (SNGPs), which provide distance awareness (i.e., awareness of how far data points are from one another). SNGPs are an innovation on traditional Gaussian Process (GP) models that bring the benefits of uncertainty estimation without a significant increase in computational complexity. GPs express uncertainty naturally - they do not just predict a single outcome but rather a distribution of potential outcomes. However, GPs can be computationally expensive, limiting their practical applications. For more details on SNGPs, check out this tutorial.
A key subroutine in SNGP is the evaluation of the softmax Gaussian posterior, using either the mean field approximation or Monte Carlo estimation. In many applications the mean-field approximation is utilized. In this tutorial however, we use Gaussian sampling and Monte Carlo to evaluate the posterior, as our hardware is naturally suited to this task.
Below, we see that in our 'two moons' classification task, using SNGPs lead to a different outcome. For in-distribution data, the model makes confident predictions; however, for OOD data, rather than making an overconfident and likely incorrect prediction as a ResNet model might, the SNGP outputs a high uncertainty, as we can see for the region with the red points.

SNGPs in the Thermo Playground
Now check this out: the SNGP example (discussed above) is integrated into the Thermo Playground! This allows the user to play with the parameters of the SPU hardware and directly see the impact on the SNGP performance! The following animation shows how the user can play with the SNGP example inside of the Thermo Playground:
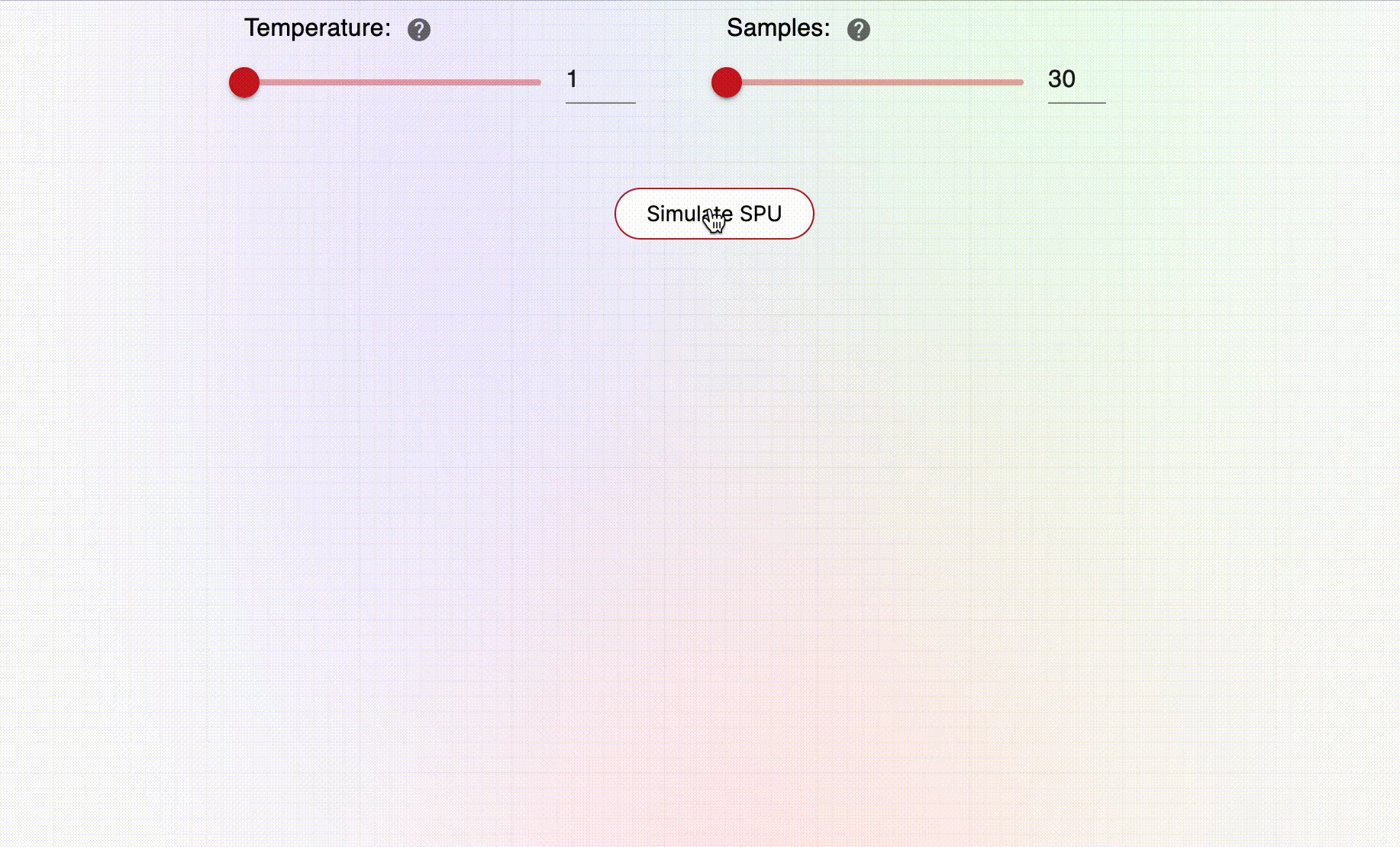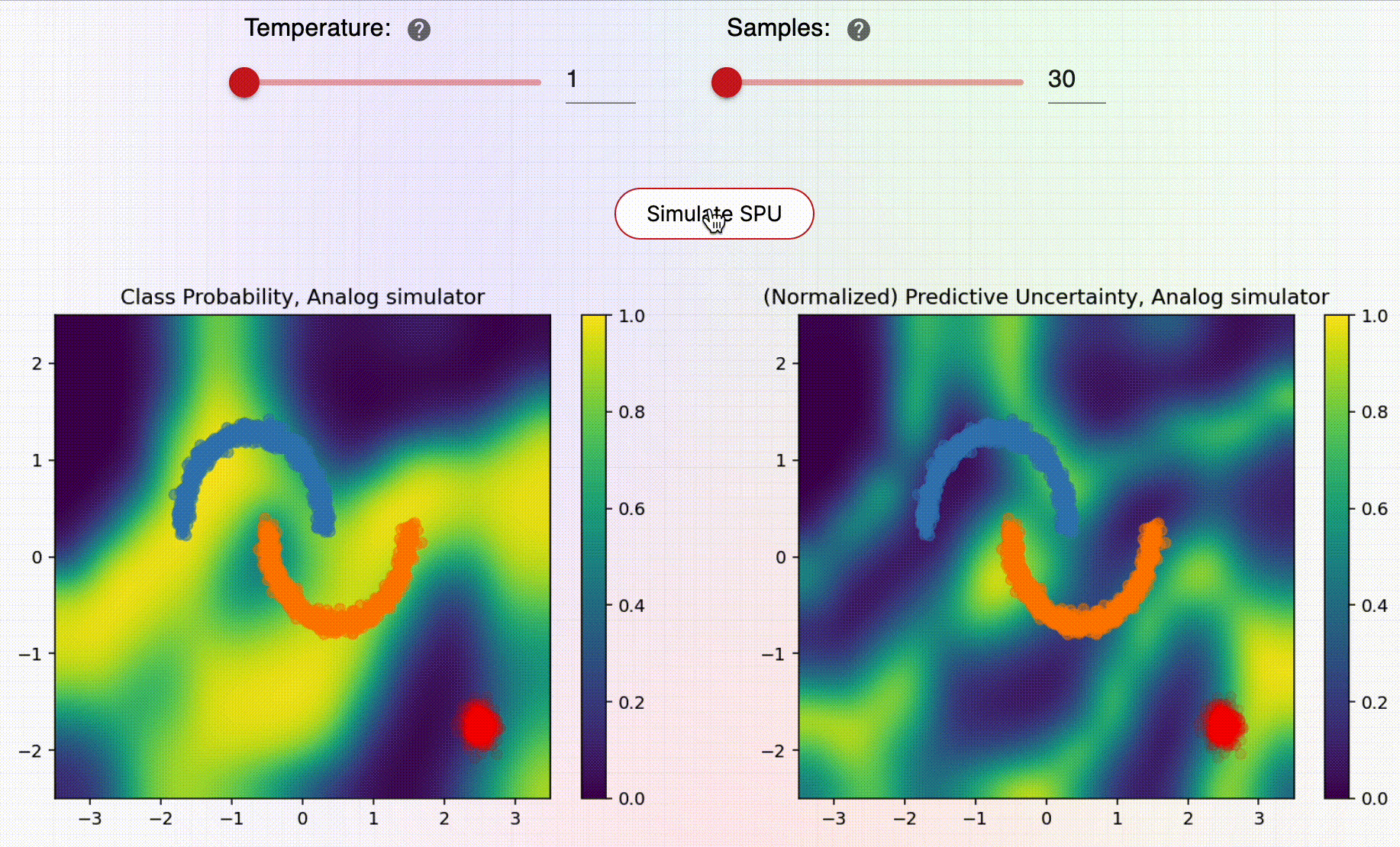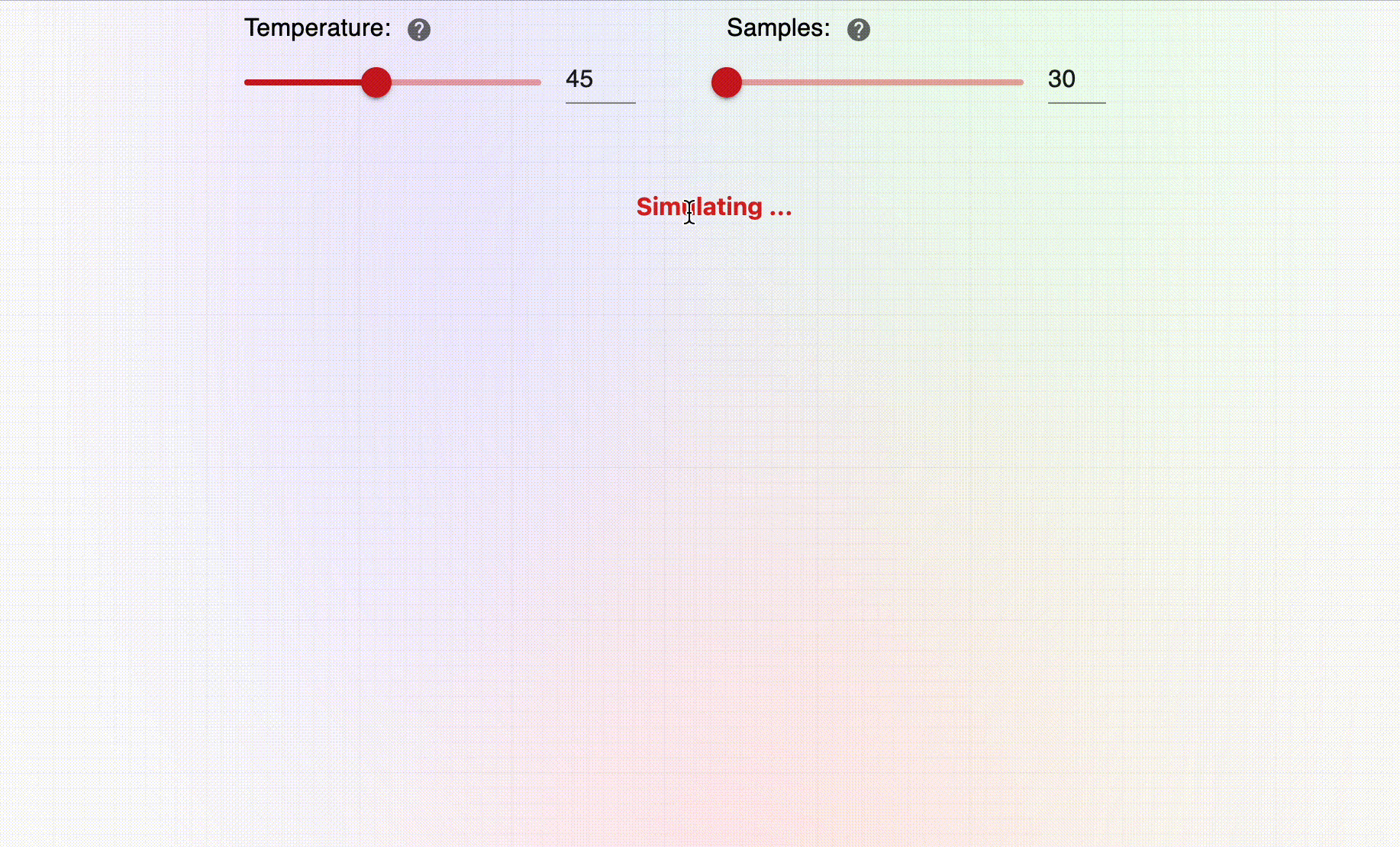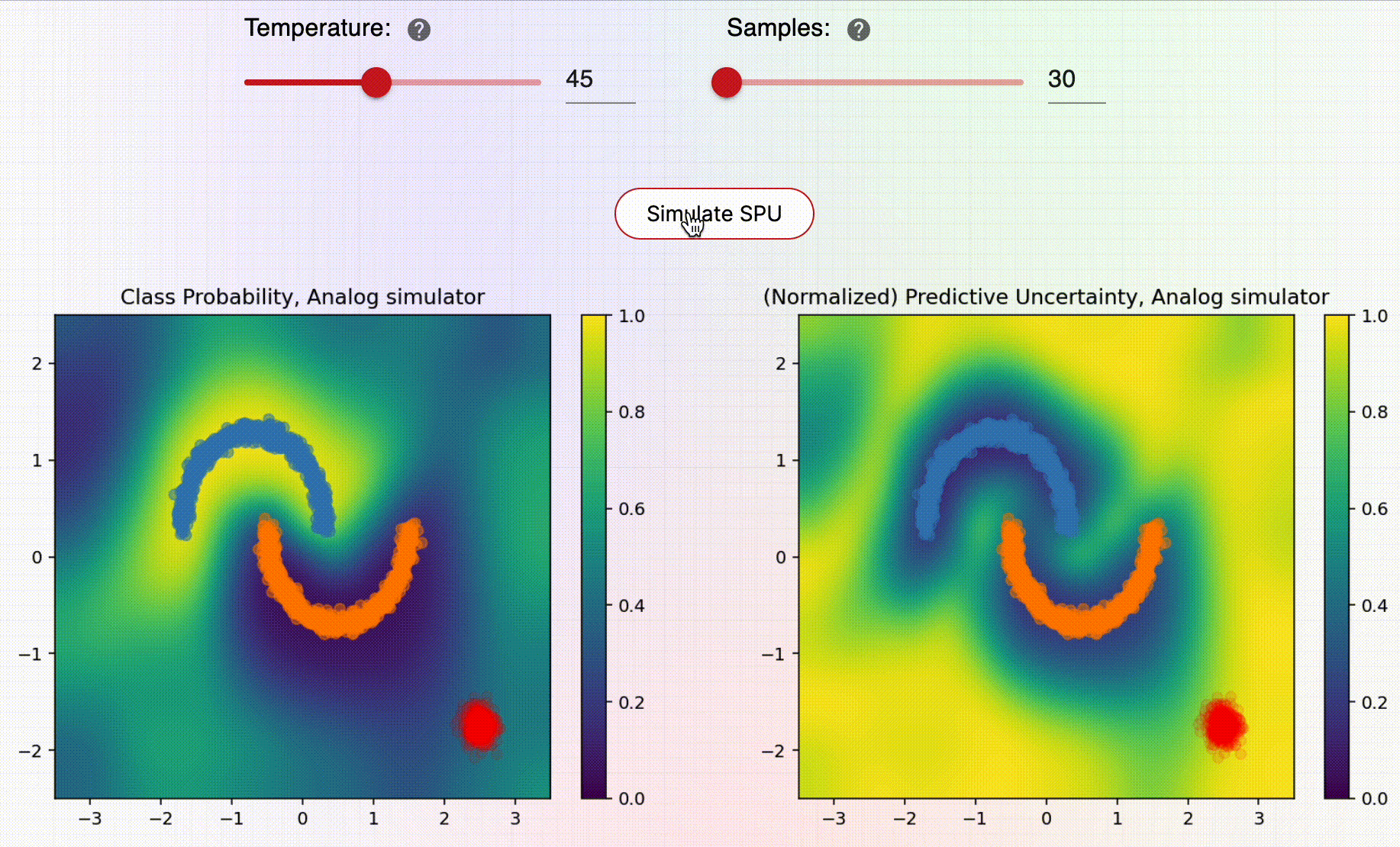
For example, the user can adjust the temperature of the stochastic noise. Increasing the temperature will reduce the correlations between samples and lead to a better overall performance of SNGP. Conversely one can see the performance starting to break down when lowering the temperature. We can also adjust the number of samples gathered, with more samples also leading to better SNGP performance.
Note that, here, we are using a simulator of the SPU to generate the samples required by the SNGP. Specifically, these are samples from a gaussian distribution whose covariance matrix is the output from the GP applied during SNGP. These samples are then used to estimate the uncertainty in predictions. So, we have shown how the SPU can be used in the context of machine learning to predict uncertainty in a simple classification task.
Below, we will discuss the exciting possibility of speedup for this type of application.
Expected Performance Advantage with SPUs
We now focus on the possible speedup one could expect from using Thermodynamic Hardware relative to state-of-the-art GPUs. Here we consider the ideal case of precise electrical components and assume the unit cells in the SPU are fully connected.
To quantify the runtime and energy consumption of the Thermodynamic Hardware, we consider the effect of three key stages: digital compilation, loading/readout and the integration time of the physical dynamics needed to generate the samples. We assume the SPU is constructed from standard electrical components operating at room temperature. For this analysis, the user provides a precision matrix (the inverse of the covariance matrix), which is then compiled to the SPU in a digital pre-processing step, and then the dynamics of the SPU are run for the time needed to generate 10,000 samples.
To get a realistic picture of the potential advantage of the SPU it needs to be compared against some of the best available digital counterparts. Therefore, digital timing/energy results below were obtained using JAX run on an A100 GPU.
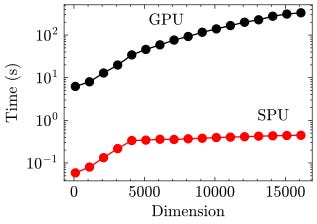
Below we show how the time taken to produce samples from a multivariate Gaussian scales with dimension. One can see that the SPU performance is expected to outperform the GPU at all dimensions. This speedup becomes exciting for high dimensional problems where we see an order of magnitude improvement.
The right hand side shows the breakdown in timings for the model of Thermodynamic Hardware when generating 20,000 dimensional samples. Interestingly, we expect the dominant step to be digital compilation. Improvements in this step would further increase the expected speedup.

Speedup is not the only thing to consider. Using the natural dynamics of a physical system massively reduces the expected energy requirements. Below we show how the energy of generating these samples is expected to scale with dimension relative to the JAX implementation.
Here we see that the performance of the SPU really begins to shine: several orders-of-magnitude in energy cost improvement are expected for high dimensional problems.
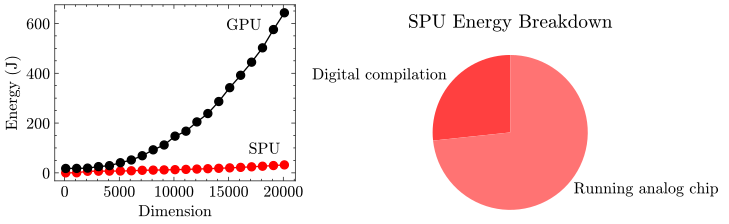
Overall, a simple model of the SPU, the timings involved in its end to end operation, and the energy cost during these processes lead to a potential speedup of an order of magnitude and energy savings of several orders of magnitude or more for this task.
Algorithmic Co-Design
We emphasize that the SNGP approach and other uncertainty-quantification (UQ) approaches were developed and optimized for deployment on digital hardware, and it is not surprising that only modest speedups are expected for these digital algorithms. This suggests an exciting possibility of co-designing the AI algorithms together with the Thermodynamic Hardware. This co-design could unlock larger speedups and energy savings than those predicted for standard digital algorithms.
In what follows, we emphasize that looking beyond SNGP towards more complicated forms of uncertainty quantification, such as Bayesian neural networks, will likely unlock even larger speedups.
The Non-Gaussian Frontier
Moving beyond Gaussian sampling one can imagine using thermodynamic hardware to produce samples from more complicated distributions, such as the posteriors of Bayesian neural networks.
In Bayesian deep learning, the model's weights follow intricate probability distributions that need constant updating during training. This process requires generating multiple samples, which makes training Bayesian neural networks computationally demanding. Considering large models with millions of parameters, sampling from such high-dimensional and complex probability distributions becomes an arduous task. In practice, hundreds of Tensor Processing Units (TPUs) may be required for accurate sampling, e.g., with Hamiltonian Monte Carlo (HMC).
We can use similar timing models to those above to investigate when one would expect a ‘thermodynamic advantage’ for this application. Using our timing model and a JAX implementation of HMC leads to the following expected speedup from an SPU tailored to beyond-Gaussian sampling.
Our model suggests that for this application, one could achieve a speedup of several orders of magnitude, with the speedup generally increasing with dimension. The potential implications would be unlocking large-scale approximation-free Bayesian deep learning. This would be a key step towards the vision of the automated statistician and automated deep learning, transforming standard deep learning into a reliable, trustworthy application.
Outlook for Thermodynamic Advantage
Generative AI technologies like Large Language Models (LLMs) suffer from hallucinations and overconfidence. This prevents GenAI from being deployed in high-stakes use cases, such as enterprise workflows or applications where human lives are at stake, like medicine, transportation, or national security.
Principled probabilistic reasoning (Bayesian methods), as we’ve discussed above, can solve these issues for GenAI. Bayesian methods output a probability distribution instead of a specific answer. Using that distribution we can compute the uncertainty of a text, say, in the context of text generation. It turns out that high uncertainty implies a likely hallucination. This gives us a direct way to detect hallucinations for LLMs or other GenAI technologies.
In this blog, we have illustrated uncertainty quantification with simple methods on a toy dataset. But ultimately, a key technological breakthrough would be large-scale reliable AI, including reliable LLMs. Achieving this goal will ultimately involve increasing the complexity of uncertainty awareness, involving methods that go beyond mean-field approximations. This is where Thermodynamic Hardware is so crucial. Simplistic, approximate methods for uncertainty quantification can be employed on today’s digital computers. But complex, high-accuracy methods are prohibitively slow, and Thermodynamic Hardware could unlock these methods.
In the figure below, we illustrate the idea of a hierarchy of uncertainty awareness. This hierarchy includes, in order of increasing complexity: mean-field variational inference (MFVI), SNGP, stochastic gradient Markov chain monte carlo (SGMCMC), and HMC. As we increase the complexity of uncertainty awareness, the potential performance gain (runtime speedup and energy savings) from Thermodynamic Hardware increases.

We emphasize that this is just a schematic plot, and there remain significant engineering challenges to be overcome to realize the large-scale hardware required for complex uncertainty awareness.
Nevertheless, the future is bright for Thermodynamic Hardware and reliable AI.
Step into the Future with Normal Computing
We invite you to try out the Thermo Playground! We hope this gives you a feel for programming actual Thermodynamic Hardware. Finally, we hope that our vision of reliable AI resonates with you.
We thank you for taking the time to read this blog post! Be sure to sign up for updates at Normal Computing’s website.
